Einfacher ist besser
Hochverfügbarkeit ist eine Herausforderung an die IT, der sich IT-Verantwortliche heute stellen müssen. Zur Wahl stehen hierfür verschiedene Lösungsansätze, doch häufig bereitet der Kostendruck zusätzlich Probleme.
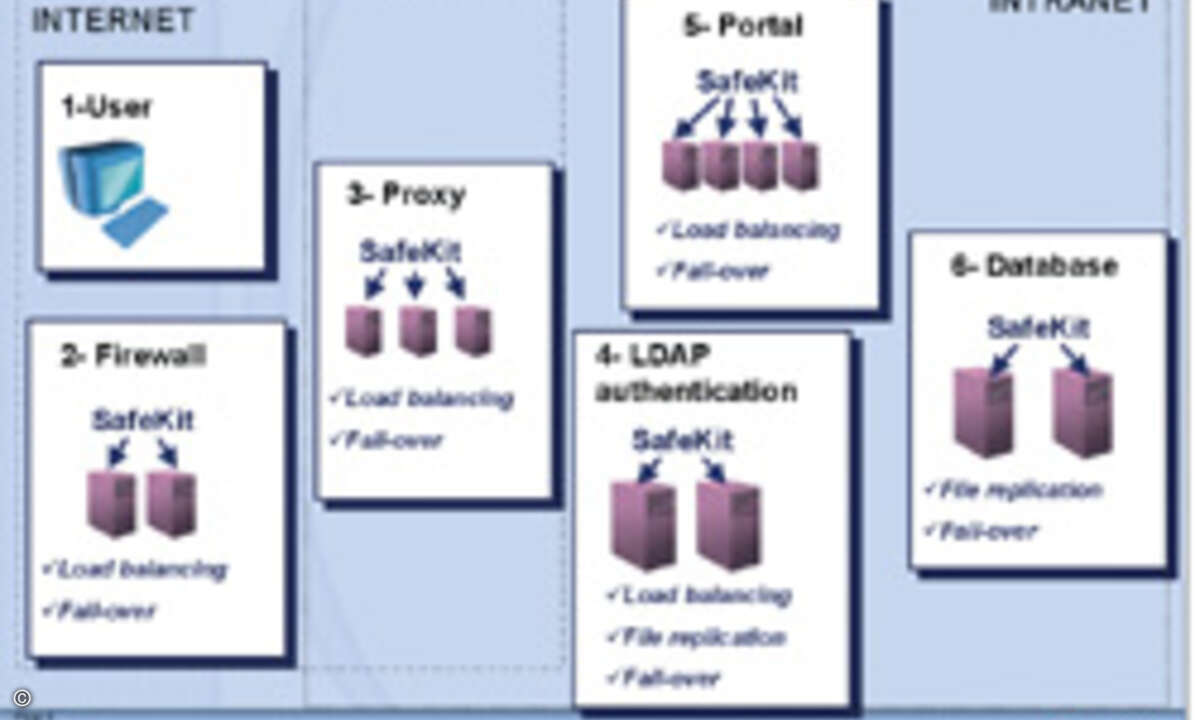
Als einzige Hardware-Investition für die gesamte Hochverfügbarkeitslösung fällt die in redundante Server-Systeme an.
Viele Unternehmen stehen vor einem Kostendilemma, einerseits müssen sie durch einen effizienteren IT-Einsatz Kosten einsparen, andererseits sind sie gezwungen, in eine höhere Verfügbarkeit ihrer Speicher-/Server-Infrastruktur zu investieren. Das fordern ihnen zunehmend onlinefähige Geschäftsprozesse ab, in die vermehrt auch Partner und Kunden einbezogen werden. Ausfälle oder Performance-Einbußen an den beiden tragenden IT-Säulen Speicher und Server können sich die Unternehmen angesichts dieses Trends zu durchgehenden Geschäftsprozessketten immer weniger leisten.
Doch wie angesichts knapper IT-Budgets den gordischen Kostenknoten durchschlagen, ohne dafür akzeptable Verfügbarkeitseinbußen bei den Geschäftsabläufen hinnehmen zu müssen? Mehr oder weniger hypothetische Modellrechnungen, welche Umsatzeinbußen zwischenzeitliche Ausfälle an einen der beiden Säulen nach sich ziehen, helfen den Unternehmen bei ihrer Rentabilitätsrechnung für die neue Hochverfügbarkeits-Lösung kaum weiter. Zumal solche Modellrechnungen ansatzweise durch Zahlen zu erhärten, wiederum Kosten nach sich zieht, ohne dass solche Kalkulationen ihren hypothetischen Charakter verlieren. Auch der drohende Imageverlust durch Ausfälle gegenüber Geschäftspartnern und Kunden, so schmerzlich er für die Unternehmen auch ist, ist erst einmal hypothetisch und zudem schwer in ein kostenrechnerisches Zahlenwerk zu gießen. Wirklich rentabel wird die neue Hochverfügbarkeitslösung für Speicher und Server, gegebenenfalls inklusive Desaster-Recovery über ein Ausweichrechenzentrum, nur dann sein, wenn sich dafür die Produkt-, Realisierungs- und Betriebskosten in engen Grenzen halten. Denn damit steigt die Wahrscheinlichkeit, dass sich die Hochverfügbarkeitslösung in jedem Fall für das Unternehmen auszahlt.
Langfristige Kostenperspektive nicht vergessen
Die richtigen Kostenweichen werden aber nicht nur mit kurzfristigem Blick auf die Produkt- und Realisierungskosten sowie mittelfristig auf die Betriebskosten gestellt. Auch mit dem Blick auf künftige Investitionen für den weiteren Ausbau der Speicher-/Server-Infrastruktur sollten die Entscheider die weiteren Kosten im Visier behalten. Eine weitgehend herstellerunabhängige Hochverfügbarkeitslösung, weil weniger hersteller- und damit preisbindend, ist langfristig gesehen bestimmt die bessere Wahl. Denn nur so löst sich das Unternehmen auf Dauer aus dem Preisdiktat weniger Hersteller. Dann profitiert es auf Dauer von einem funktionierenden Preiswettbewerb, einer breiteren Produktauswahl, einer herstelleroffeneren Lösungsauslegung sowie einem höheren Investitionsschutz. Unterschiedliche Ansätze erschweren den Durchblick, welche generelle Produktstrategie die Entscheider fahren sollten, um ihrer Speicher-/Server-Infrastruktur kostenverträglich Hochverfügbarkeit zu verleihen? Zumal ihnen die Hersteller die Auswahl und den Kostendurchblick nicht gerade einfach machen. Dabei sind es, wie gesagt, nicht allein die Produktkosten, die für die angestrebte Rentabilität der umfassenden Hochverfügbarkeitslösung entscheidend sind. Je nach Komplexität und Heterogenität der Gesamtlösung können sich dahinter zudem hohe Integrationskosten verbergen – ebenso wie später hohe Betriebskosten für viele zu administrierende Teillösungen. Und: Erweist sich die Infrastruktur der anvisierten Hochverfügbarkeitsinstallation als hoch komplex, steigt damit auch die Fehleranfälligkeit innerhalb der IT, der man eigentlich mit der Hochverfügbarkeitsinitiative entgegenwirken wollte.
Für die Hersteller im SAN-Bereich steht außer Frage, dass sie die richtige Lösung für eine höhere Verfügbarkeit der IT offerieren, allerdings lediglich für die Speicher-Seite. Aber die SAN-Technologie ist weiterhin komplex und zudem mit beachtlichen Investitionen in Hard- und Software verbunden. Das sind vor allem:
- Die Fiber-Channel-Switch-Systeme inklusive redundanter Auslegung (Dual-Fabric),
- neue Online- sowie Nearline-Speichersysteme für Desaster-Recovery,
- komplexe Tools zur Verwaltung der SAN-Infrastruktur sowie der Datensicherung auf Band im Rahmen von Desaster-Recovery.
Nicht vergessen werden sollte die zeit- und damit kostenaufwändige Projektierung, auch weil sich die komplette SAN-Lösung in der Regel aus Komponenten vieler Hersteller zusammensetzt, die dennoch nahtlos zusammenwirken müssen. Nicht bei der Entscheidung »Hochverfügbarkeit« vergessen werden sollte zudem, dass der Betrieb eines komplexen SAN eine reine Spezialistenaufgabe ist, mit allen damit verbundenen Personal- oder zumindest Schulungskosten. Zwar eröffnet das SAN viele Vorteile wie:
- Mehr Transparenz über alle Speichersysteme.
- Klare Trennung von Speichersystemen und Applikations-Servern via Managementschicht: Dadurch können Speichersysteme unterschiedlicher Hersteller eingesetzt werden, alle Applikations-Server auf jede beliebige Speichereinheit zugreifen und gemeinsam mit anderen die selben Daten nutzen (True-Data-Sharing).
- Einzelne Speichereinheiten und Applikations-Server sind über virtuelle Verbindungen gruppierbar, dadurch kann der Verkehr der einen Gruppe sicher von dem anderer Gruppen isoliert werden (Zoning).
- Speicher-Virtualisierung und Zoning – beide ermöglichen es, Online- wie Nearline-Speicher kostensparend zu konsolidieren.
Doch der genaue Blick auf diese Vorzüge zeigt, dass insbesondere Unternehmen mit großen, heterogenen Installationen und einem sehr hohen Bedarf an Online- und Nearline-Speicherkapazitäten davon profitieren. Für Installationsgrößen, in denen sich das Gros der Unternehmen wiederfindet, erweisen sich diese Vorzüge und die Mittel, sie zu erreichen, dagegen als überdimensioniert. Auch wenn Hersteller im SAN-Bereich mit aller Vehemenz versuchen, selbst mittelständische Unternehmen vom Gegenteil zu überzeugen.
NAS wird dagegen eher als einfache und kostengünstige Lösung gepriesen. Immerhin baut NAS in seiner originären Form auf dem klassischen Datei-Server-Konzept auf. Das NAS-System erlaubt es, File-Server und die daran angeschlossenen Plattensysteme hoch verfügbar auszulegen sowie die angeschlossenen Clients performant mit allen notwendigen Daten zu beliefern. Dieser Hochverfügbarkeitsansatz verliert aber schnell seinen Charme der Einfachheit, wenn über Datei-Server mit ihren Platteneinheiten hinaus Datenbanken eingebunden werden müssen. Dann müssen nämlich kostspielige Zusatzlösungen eingesetzt werden, die die von den Datenbanken belegten Bereiche, statt auf Platte, als Dateien auf den NAS-Servern hinterlegen und die beim Zusammenspiel von Datenbank, Datenbank-Server und NAS-System für die notwendige Performance sorgen.
Soll dem NAS-System zusätzlich in Verbindung mit Bandlaufwerken Desaster-Recovery-Fähigkeit verliehen werden, sind weitere kostspielige Werkzeuge wie Snapshot oder Remote-Copy notwendig. Nur dann ist das NAS-System per Serverless- oder Lanless-Backup in eine zentrale Backup-Lösung integrierbar. Im ersten Fall wird das Risiko eines Applikations-Server-Ausfalls umgangen, indem Zusatzwerkzeuge wie Remote-Snapshot oder Remote-Copy die Daten von Platte nehmen und unter der Führung des Datensicherungs-Servers via LAN auf Band schreiben. Im zweiten Fall werden die Applikations-Server vorbei am LAN initiativ und führen über den Datensicherungs-Server das Backup auf Band aus. Ein Ausfall des lokalen Netzwerkes bringt damit das Backup nicht ins Stocken. Die Komplexität der NAS-Lösung ebenso wie der Projektierungs- und später des Betriebsaufwands wächst allerdings mit all diesen Zusatzwerkzeugen erheblich. Zumal solche Tools von unterschiedlichen Herstellern stammen.
Server-Cluster als potenzielle Lückenfüller
Darüber hinaus lassen SAN wie NAS mit ihrem alleinigen Fokus auf Speichersysteme die Hochverfügbarkeitslücke »Applikations-Server« außen vor. Um ihre Verarbeitung hochverfügbar auszulegen, muss zusätzlich beispielsweise in plattformspezifische Cluster-Lösungen einschließlich Datensynchronisation investiert werden. Datensynchronisation ist notwendig, um den Platteninhalt von Primär- und Sekundär-Server für einen schnellen Umstieg permanent auf dem gleichen, aktuellen Stand zu halten. Solche plattformspezifischen Cluster-Lösungen verkomplizieren in heterogenen Server-Umgebungen die Gesamtinstallation und ihre Projektierung weiter, ebenso wie später ihren Betrieb mit jeweils separater Administrierung unter spezifischer Bedienerführung. Eine Clustering-Lösung unter zentraler Strategie und Führung ist damit innerhalb einer heterogenen Server-Umgebung nicht möglich. Selbst einige große Dienstleister, die sich Hochverfügbarkeit auf ihre Fahne geschrieben haben, scheitern heute immer noch an diesem plattformspezifischen Clustering-Zuschnitt. Sie lassen dadurch zum Leidwesen ihrer hilfesuchenden Kunden bei einzelnen Server-Plattformen schmerzliche Unterstützungs- und Realisierungslücken.
Soll bei der Verarbeitungsleistung zusätzlich an der Performance-Schraube gedreht werden, muss zwischen jedem wichtigen Applikations-Server-Paar außerdem Load-Balancing für eine gleichmäßige Lastverteilung im Normalbetrieb zum Einsatz kommen. Auch das verursacht hohe Zusatzkosten sowie einen weiteren Komplexitäts- und Administrationsschub innerhalb der Hochverfügbarkeitsinstallation. Doch selbst dann greift Load-Balancing nicht in jedem Fall dort, wo es greifen sollte, nämlich direkt auf den Applikations-Servern. Gerade bei Load-Balancing-Lösungen mit herstellerspezifischem Plattformzuschnitt funktioniert die automatische Lastverteilung oftmals nur auf den nachgeordneten Servern, beispielsweise Web-Servern. Das aber trägt nur mittelbar und dadurch unzureichend zu den erwarteten Performance-Steigerungen bei den Verarbeitungsleistungen bei.
Der Teilfokus von Herstellern liegt auf einzelnen Bereichen der Hochverfügbarkeit wie Speichersystemen oder Applikations-Servern, insgesamt zu vielen Komponenten, die im Sinne einer Gesamtlösung zusammenwirken müssen. Dazu handelt es sich zumeist um proprietäre und plattformabhängige Lösungszuschnitte. Das alles führt in der Summe schnell zu einer zu kostspieligen, komplexen, projekt- und betriebsaufwändigen sowie herstellerbindenden Hochverfügbarkeitsinstallation. Eine Hochverfügbarkeitslösung, die in all diesen Punkten dagegen überzeugen soll, müsste dementsprechend aufwarten durch:
- Volle Funktionsabdeckung im Sinne einer Gesamtlösung,
- einfachere Lösungsstrukturen mit weniger Komponenten und Werkzeugen,
- vorgefertigte Integration,
- Plattformunabhängigkeit sowie
- eine über alle Hochverfügbarkeitsdisziplinen und Server-Plattformen weitgehend einheitliche Bedienerführung.
Zudem müsste eine solche Gesamtlösung, um sich als kostengünstig in der Anschaffung sowie als einfach in der Umsetzung und im Betrieb zu erweisen, einen generellen Hochverfügbarkeitshebel für beide Domänen, die Daten- und Applikations-Seite, etablieren. Das ist möglich, weil nicht nur auf der Applikations-Seite, sondern auch auf der Datenseite der Verfügbarkeitshebel an den Servern, nämlich den Datei- und Datenbank-Servern, durch ihre doppelte Auslegung angesetzt werden kann. Selbst mit Blick auf Desaster-Recovery ist diese kostengünstigere und einfachere Herangehensweise durchhaltbar. Neben dem Sekundär-Dateien- und -Daten-Servern kann ein weiterer Tertiär-Server in einem anderen Gebäude platziert werden, der für schnelle Backups und Restores automatisch in die Datensynchronisation einbezogen wird. Historische Massendaten ohne die Anforderung eines schnellen Auf- und Zurückspielens können dann immer noch für Analyse- und Revisionszwecke in einem weiteren Schritt auf Band hinterlegt werden, ohne dass dazu in teure Speichertechnologien, in aufwändige Projektierungsmaßnahmen und in das Austesten komplexer Notfall-Szenarien investiert werden muss.
Immerhin bietet der Markt bereits solche Hochverfügbarkeits-Komplettlösungen, die den Hebel parallel auf der Daten- und der Applikations-Seite ansetzen. Zu 100 Prozent in Software realisiert schließen sie Fail-over/Fall-back, Datensynchronisation und bei Bedarf Load-Balancing im Normalbetrieb ein. Die Software läuft ohne großen zusätzlichen Ressourcenverbrauch einfach auf dem Server mit. Neue Einträge werden parallel zur Ausführung der Datenzugriffe oder Applikationen auf Platte geschrieben. Dadurch gerät die Datensynchronisation zwischen den Platten nie in Verzug. Als einzige Hardware-Investitionen für die gesamte Hochverfügbarkeits-Komplettlösung fallen ausschließlich die in redundante Server-Systeme an, weil alle notwendigen Hochverfügbarkeits-Funktionalitäten inklusive dynamischer Lastverteilung durch die Software abgedeckt werden.
Anders als beim Server-Clustering kann die über alle Funktionen voll integrierte Hochverfügbarkeitslösung auf allen marktwichtigen Server-Plattformen wie Windows-NT, Windows-2000, Sun-Solaris, HP-UX, IBM-AIX und Linux zum Einsatz kommen. Die Bedienerführung über die komplette Installation ist dabei soweit wie möglich identisch. Das vereinfacht und verbilligt auch den Betrieb der Komplettlösung. Dadurch kann beispielsweise der selbe Administrator oder Operator unterschiedliche Server-Plattformen parallel und strategiekonform betreuen.
Auch die Installation der integrierten Hochverfügbarkeits-Software auf den unterschiedlichen Daten- und Applikations-Servern geht verhältnismäßig schnell über die Bühne. Eingriffe in Programme, ein wesentlicher Zeitfaktor bei der Realisierung, müssen nicht vorgenommen werden, da die Datensynchronisation ausschließlich auf Dateiebene stattfindet. Zusätzlich beschleunigen Plug-and-Play-Lösungen für marktwichtige Datenbanken, Anwendungen, Netzdienste, Management- und Sicherheitssysteme die Implementierung und drücken dadurch die Realisierungszeit pro Server-Verbund deutlich unter die Drei-Tage-Marke. Beispielsweise offeriert Evidian ihre integrierte Hochverfügbarkeits-Software Safekit als Plug-and-Play-Lösung für mittlerweile rund fünfzig gängige Systeme.
Fazit
Unternehmen normaler Größenordnung, die keine großen, heterogenen Server-Installationen im Einsatz haben und deren absehbarer Online-Speicherbedarf sich unterhalb der 1-Tera-Byte-Marke bewegt, kommen blendend mit einer einfacheren Hochverfügbarkeitslösung wie Safekit aus. Zumal sie sich ihnen über die Etappen »Produktkosten«, »Projektierung« und »Betrieb« in einer Kostenrelation erschließt, die eine schnelle Rentabilität dieser Lösung sehr wahrscheinlich macht. Dipl.-Ing. Walter Trojan, Consultant und Marketier, Evidian