Lost in Translation? Not at all!
Für die Erschließung neuer internationaler Märkte und für den globalen Handel benötigen Unternehmen immer mehr Übersetzungen und Lokalisierungen. Neue Lösungen auf Basis von maschinellem Lernen und Künstlicher Intelligenz versprechen in diesem Zusammenhang, mitunter preisgünstige Abhilfe.

- Lost in Translation? Not at all!
- Erschließung neuer Märkte und Platzierung neuer Angebote
Sei es der digitale Sprachassistent auf dem Smartphone, die automatische Analyse von Maschinendaten oder etwa intelligente Smart-Home-Anwendungen zur Fernsteuerung von Haushaltsgeräten: Künstliche Intelligenz (KI) ist Teil unseres Alltags geworden. Nachdem ihre Entwicklung jahrzehntelang in Forschungslaboren stattfand, geben sich Entwickler mittlerweile die Klinke in die Hand, um KI-basierte Applikationen als Teil innovativer Business Cases auf den Markt zu bringen und Nutzern aus vielen verschiedenen Industrien und in jeder Lebenslage dafür zu begeistern. Die Verarbeitung natürlicher Sprache gehört dabei zu den frühesten KI-Anwendungen, die für öffentliches Interesse sorgten. Ein prominentes Beispiel ist die automatische Übersetzung von Texten.
Nach dem anfänglichen Hype um das Thema in den 1950er-Jahren wurde schnell klar, dass die Qualität menschlicher Übersetzung mit den Resultaten der damals bekannten Methoden kaum vergleichbar war. Mehrere Jahrzehnte lang wurde in Grundlagenforschung investiert – bis mithilfe neuronaler Netze der entscheidende Durchbruch kam. Bis heute sind sie einer der wichtigsten Bestandteile hochqualitativer Übersetzungsprozesse.
Anbieter zum Thema

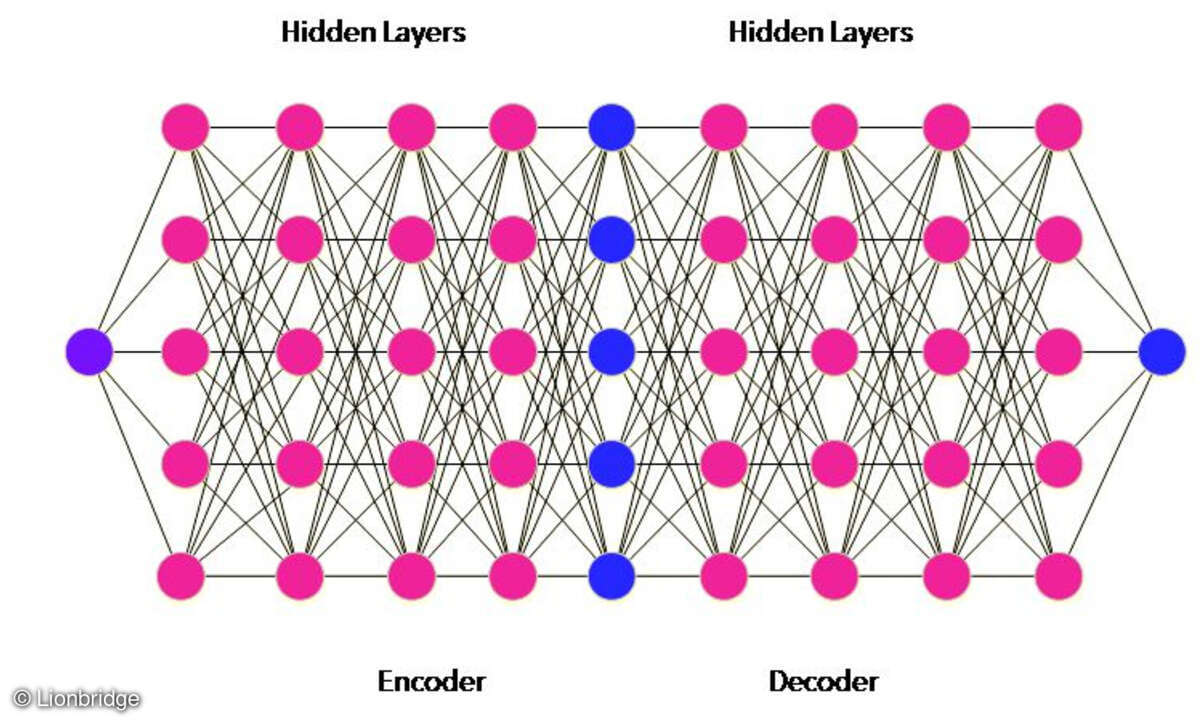
Der Durchbruch von KI-Methoden und neuronalen Netzen
Neuronale Netze sind indes keine neue Technologie. Erste kleinere Prototypen zur Lösung von Teilproblemen waren schon in den frühen 80er-Jahren entwickelt worden. Bei komplexeren Anwendungsfällen stieß man jedoch schnell an die Grenzen der Möglichkeiten, wie zum Beispiel die hohe Rechenintensität für die Verarbeitung solcher Netze. Das liegt zum Teil auch daran, dass sich neuronale Netze stark an Aufbau und Funktionsweise von komplexen biologischen Netzen orientieren: Definierte Neuronen beziehungsweise Netzknoten sind mit anderen Knoten verknüpft und bilden so eine Anordnung miteinander kommunizierender Knoten. Noch klarer wird das Funktionsprinzip am Beispiel der neuronalen maschinellen Übersetzung: Für jedes Wort und jeden Satz der Ausgangssprache wird ein Vektor erzeugt. Mithilfe dieser Vektoren können alle Eigenschaften von Wörtern oder Sätzen in ihren unterschiedlichsten Zusammenhängen abgebildet werden. Für die Übersetzung mit neuronalen Netzen werden Elemente der Zielsprache erst in Form einer Zwischenrepräsentation kodiert („Encoder“) und in einem weiteren Schritt dann mithilfe eines „Decoders“ in die Zielsprache übersetzt. Die Verarbeitung geschieht in sogenannten „Hidden Layers“. Alle Verbindungen zwischen den einzelnen Knoten sind dabei konfigurierbar, sodass bestimmte Verbindungswege durch ein neuronales Netz gegenüber anderen Pfaden bevorzugt werden können. Ein Netz kann anhand von Beispieldaten auf die Lösung bestimmter Problemstellungen trainiert werden, wodurch ein Netz mit gewichteten Pfaden entsteht. Auf Basis eines derart trainierten Netzes können Lösungen für ähnliche Problemstellungen gefunden werden.
Notwendige punktuelle Verbesserungen und Anpassungen an neue Sachgebiete und Textsorten können nur mithilfe von Re-Trainings auf Basis veränderter Daten gemacht werden. Und eben darin liegt wiederum der Kern des Ansatzes: Für das Training neuronaler Netze braucht es einerseits sehr große Datenmengen, die andererseits aber auch repräsentativ sind für den geplanten Verwendungszweck und wenige Tipp- oder Satzzeichenfehler und dergleichen aufweisen. Das Training auf Basis der geforderten Datenmengen sowie die Verarbeitung von Texten sind äußerst aufwendig. IT-Systeme, die solchen anspruchsvollen Anforderungen gewachsen sind, befinden sich erst seit wenigen Jahren auf dem Markt: Sowohl hardwareseitige Neuerungen als auch vollständig neue Datenbanktechnologien erlauben eine effiziente Verarbeitung neuronaler Netze.
Aktuelle Entwicklungen als Innovationstreiber
Erst in den vergangenen paar Jahren wurde der Zugriff auf große textuelle Datenmengen ermöglicht, genauso wie auf Technologien zur stark automatisierten Qualitätssicherung von Massendaten. Das Training neuer Netze erfolgt automatisch, was die Entwicklungszeit von Übersetzungsmaschinen für neue Übersetzungsrichtungen, Sachgebiete oder Textarten optimiert. Gleichzeitig entfällt die aufwändige Programmierung neuer Modelle durch IT- und Computerlinguistik-Experten fast vollständig. Die Evaluierung der Übersetzungsqualität durch Tests anhand von Beispielmodellen erfordert nach wie vor den Einsatz von Sprach- und Übersetzungsexperten.
Zwar sind die Erfahrungen mit neuronaler maschineller Übersetzung noch relativ gering, die Einführung neuronaler Netze dürfte jedoch jetzt schon einen Paradigmenwechsel anstoßen: Bereits heute ergeben sich viele neue Business Cases aufgrund der Tatsache, dass die Übersetzungsqualität solcher Systeme in einigen Fällen ein sehr hohes Niveau erreicht. Dadurch kann humane Nachbearbeitung zur Qualitätssicherung auf ein Minimum reduziert werden oder in manchen Fällen ganz entfallen. So wird die Zeit bis zur Verfügbarkeit mehrsprachiger Information stark reduziert bei gleichzeitig reduzierten Kosten.