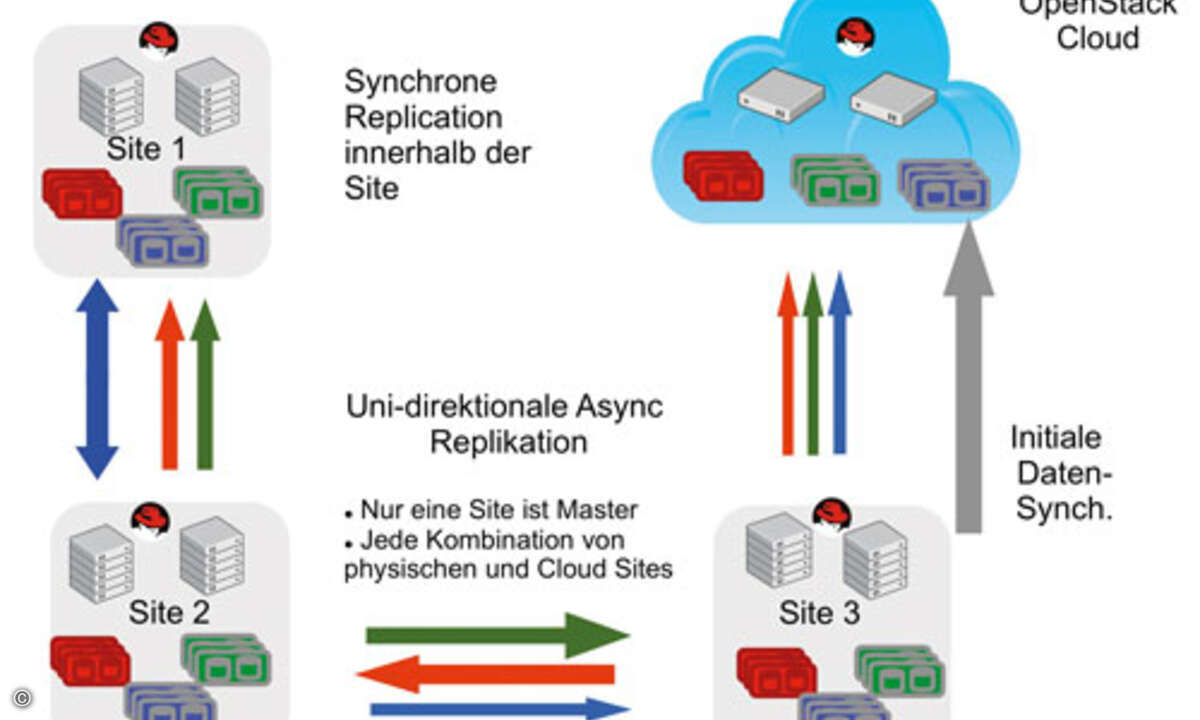
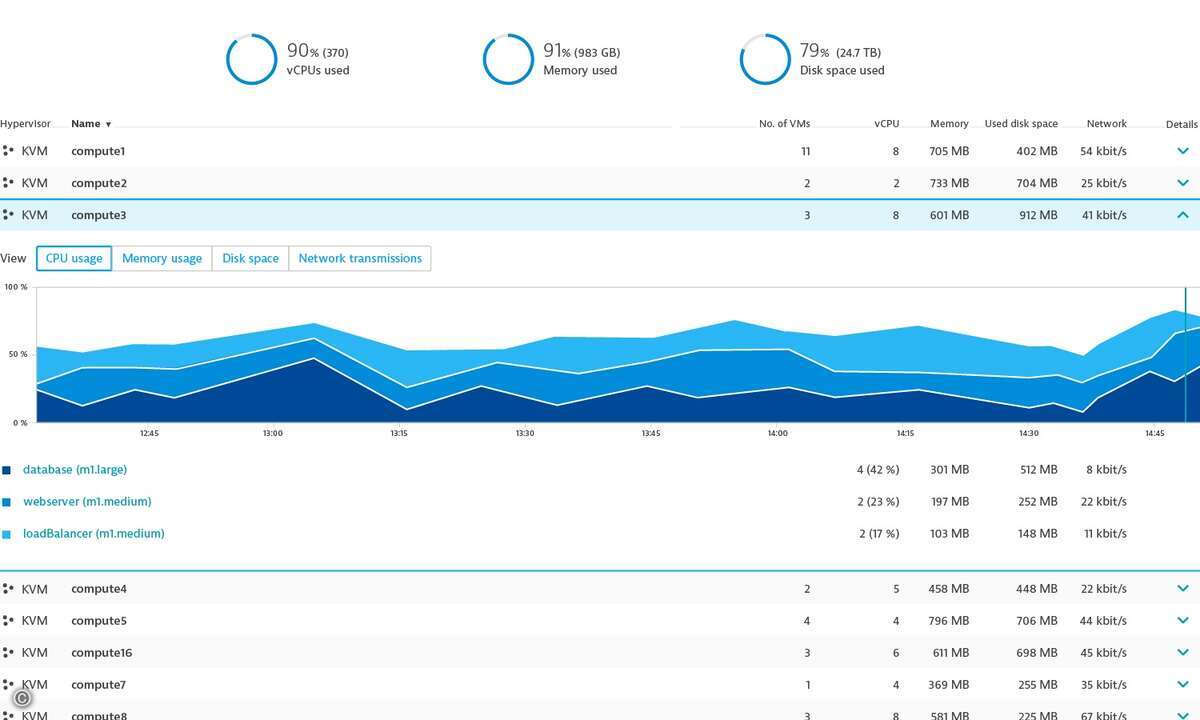
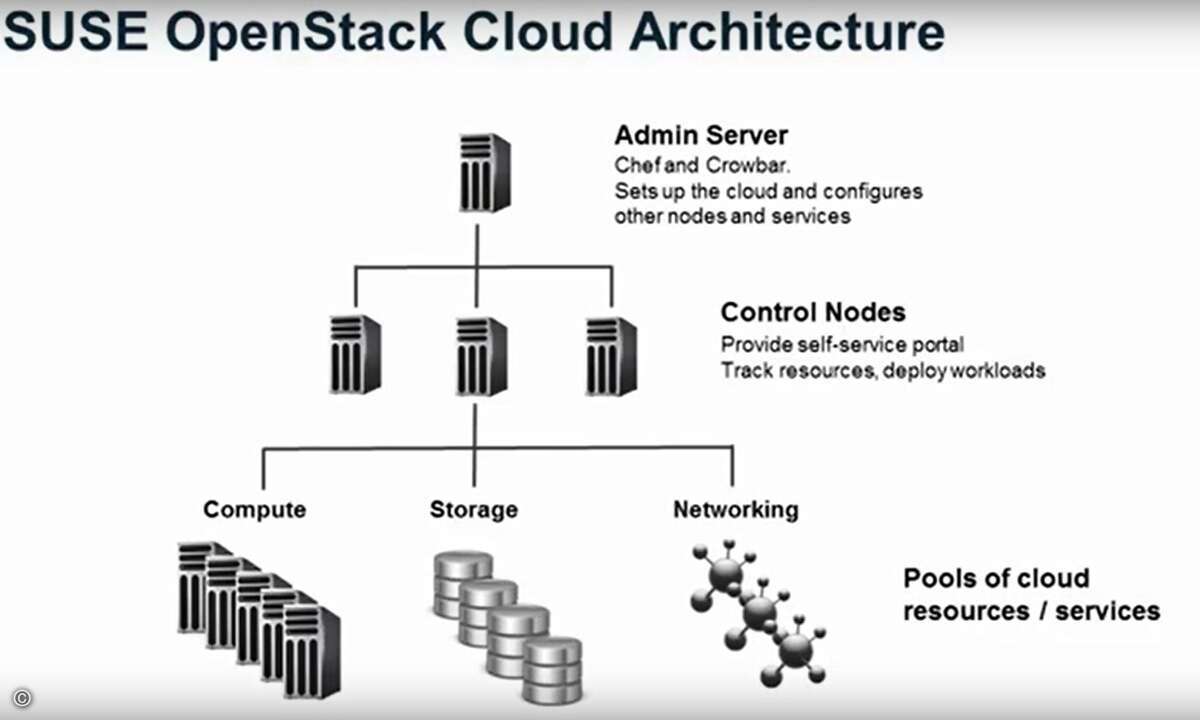
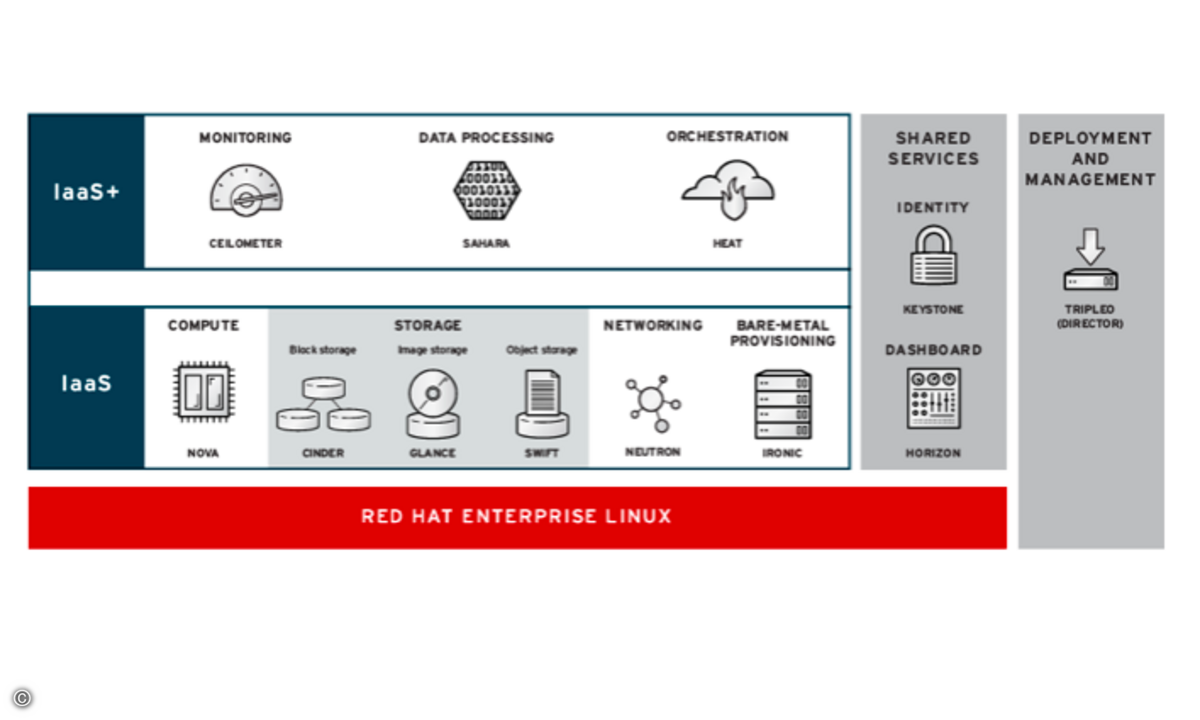
Für den Notfall gerüstet
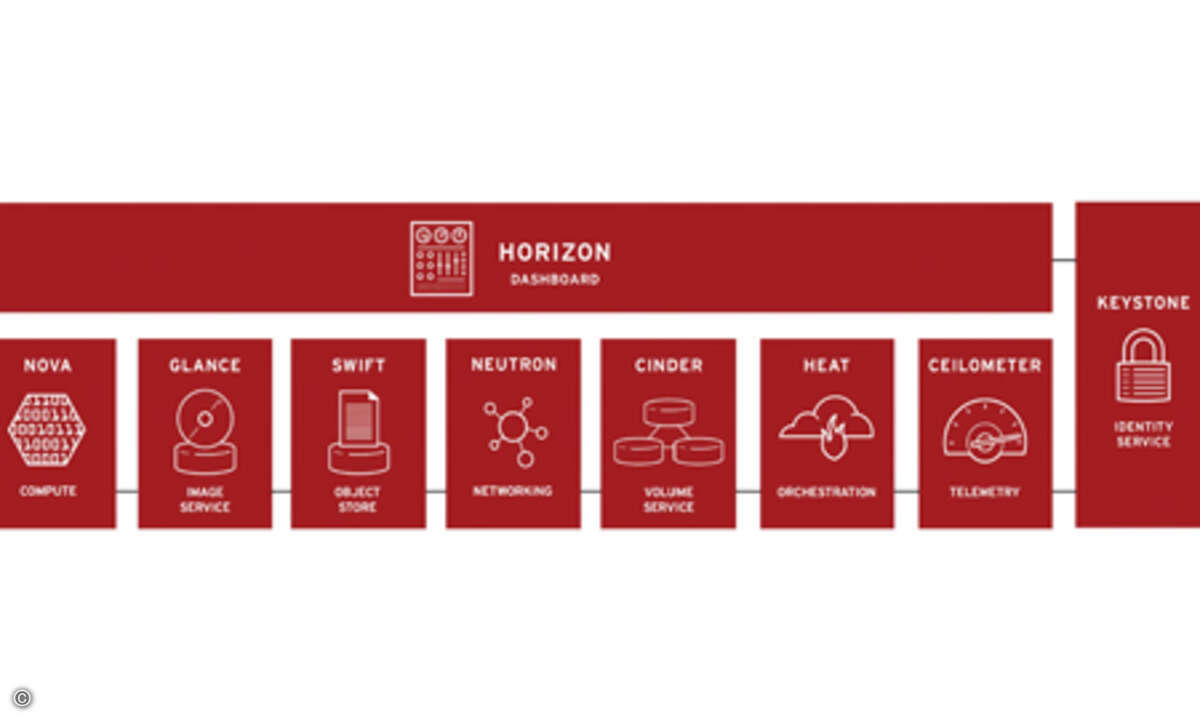
Disaster Recovery für Openstack ist der Oberbegriff für Aktivitäten, mit denen sich Cloud-Applikationen und -Services nach einem Systemausfall wiederherstellen lassen. Die Implementierung von Disaster-Recovery-Maßnahmen erfordert APIs in den Openstack-Storage-Komponenten, mit denen Administratoren gezielt Funktionen aufrufen und steuern können.Die Anforderungen an die Unternehmens-IT ändern sich schneller als je zuvor. In immer kürzeren Abständen besteht Bedarf, vorhandene Applikation zu erweitern und die Applikationslandschaft um externe, komplexe Pakete sowie um neuartige Apps zu ergänzen. Gleichzeitig steigen damit auch die Anforderung an das Backup und die Wiederherstellung der Daten nach einem Systemausfall. Im Cloud-Zeitalter nimmt die Komplexität weiter zu, besonders in einem Hybrid-Cloud-Betriebsmodell. Wenn es um die Planung und Implementierung von Open-Hybrid-Cloud-Infrastrukturen geht, fassen immer mehr Unternehmen Openstack als Fundament einer Cloud-Integrationsstrategie ins Auge. Openstack ist ein Projekt, das gemeinsam von Entwicklern und Cloud-Computing-Anbietern gestartet wurde und das in der Zwischenzeit ein breiter Kreis von IT-Anbietern, darunter beispielsweise auch Red Hat, unterstützt und weiterentwickelt. Konsens besteht darin, dass Unternehmen mit dem Openstack-Framework unterschiedliche Arten von Cloud-Infrastrukturen aufbauen und bereitstellen können. Eine Openstack-Cloud-Infrastruktur besteht aus Rechenleistungen (Compute), Speicherkapazitäten (Storage) und Netzwerkkomponenten. Openstack unterstützt drei Storage-Modi: "File"-, "Block"- und "Object"-Storage. In aller Regel kommt File Storage für unstrukturierte Daten wie Dokumente, Präsentationen oder Spreadsheets zum Einsatz. Block Storage eignet sich für strukturierte Datenbanken und lässt sich wie eine externe Festplatte mit einer virtuellen Instanz verbinden. Einsatzgebiet von Object Storage wiederum ist das langfristige Speichern statischer Daten. Typische Anwendungsszenarien dafür sind