Big Data beherrschbar machen
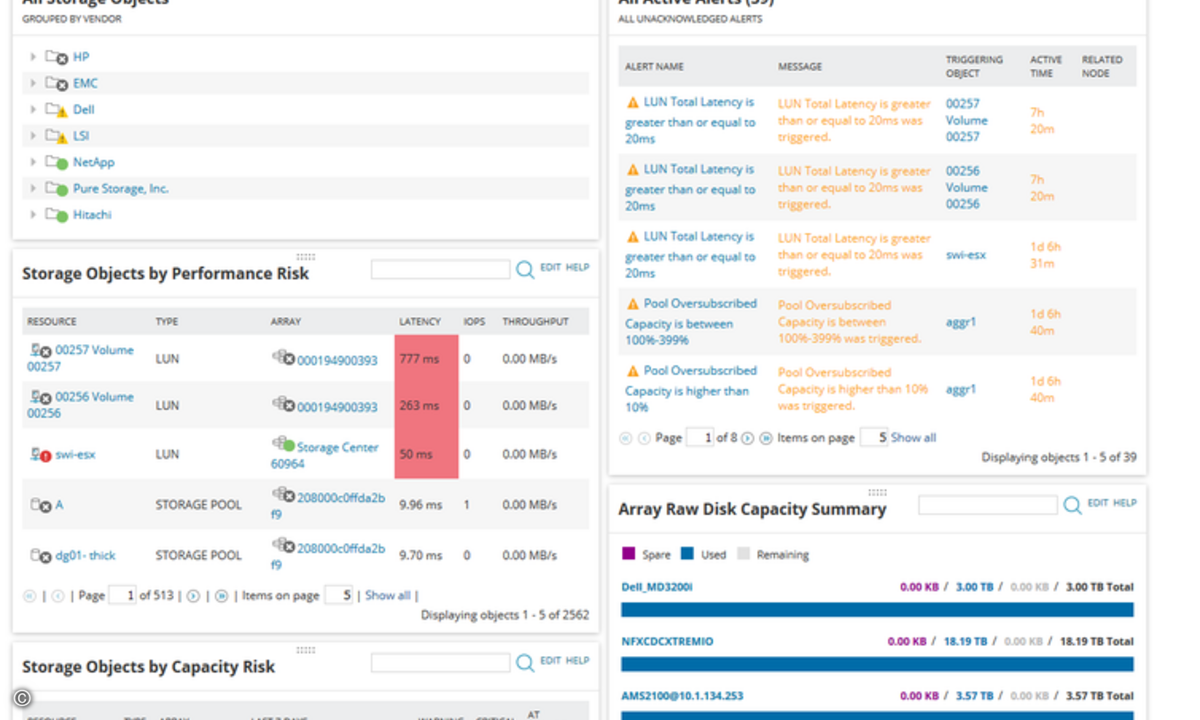
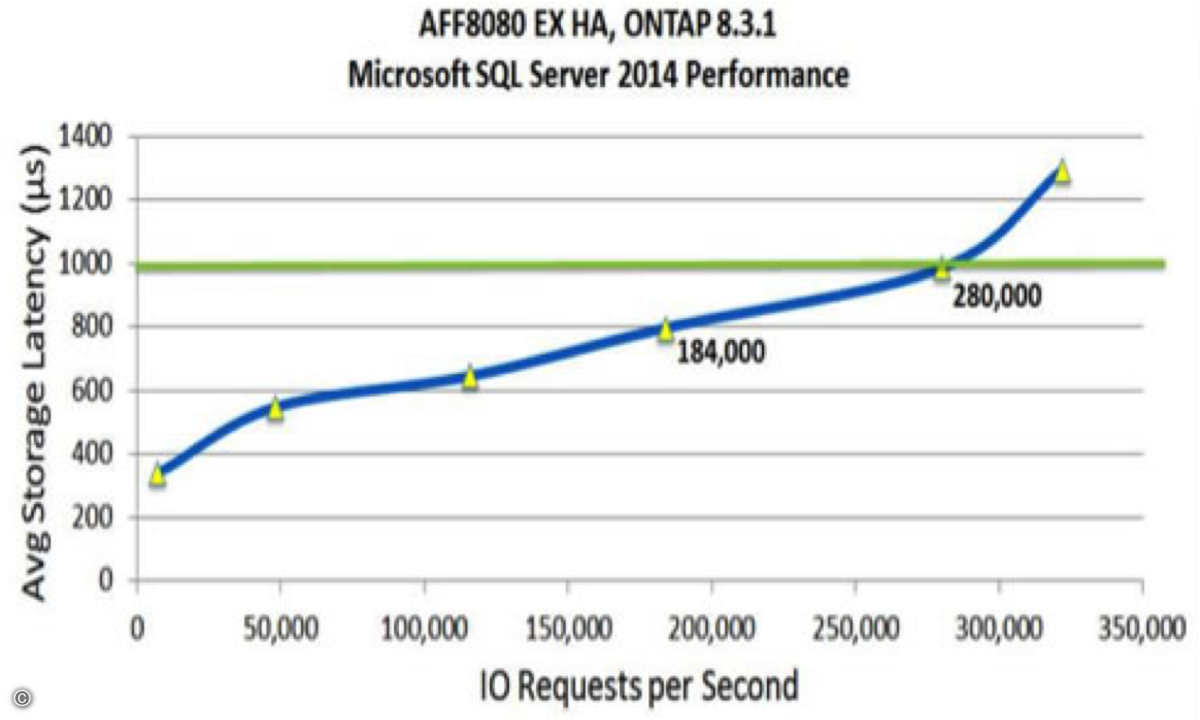
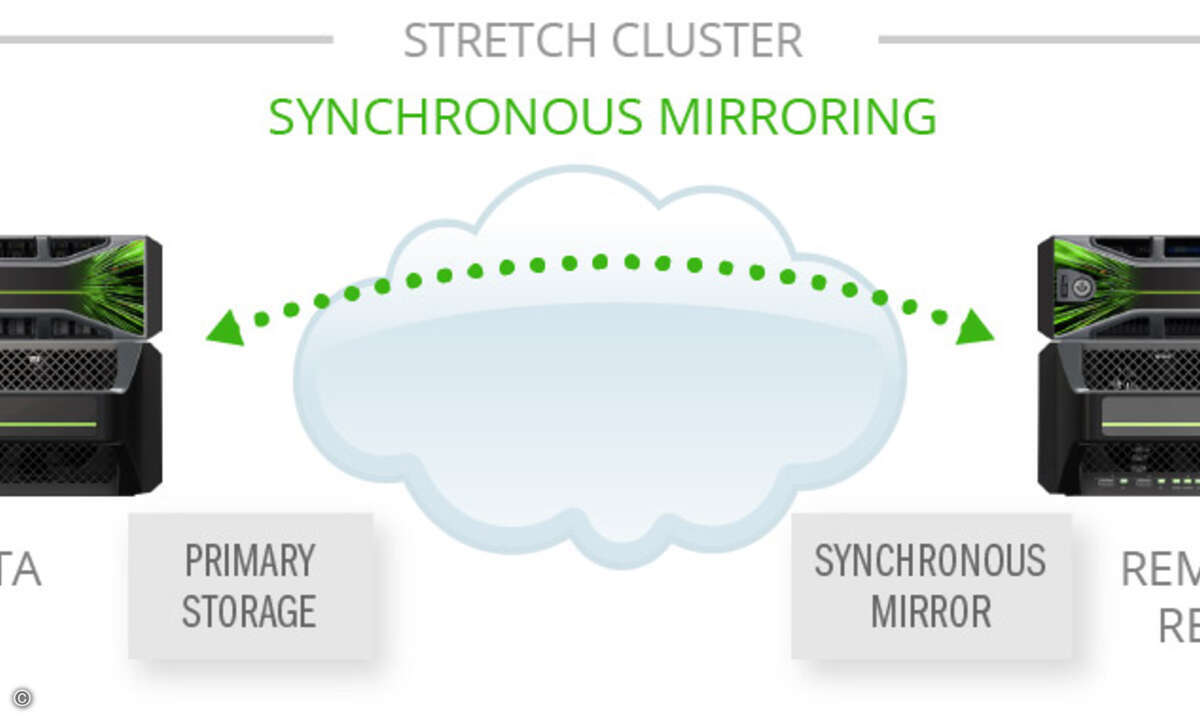
"Big Data" stellt für Unternehmen eine große Herausforderung dar: Virtualisierung und moderne Business-Applikationen erfordern zunehmend mehr Speicherkapazität - zugleich aber auch höchste Performance beim Lese- und Schreibzugriffen. Beide Anforderungen gemeinsam lassen mit klassischen Storage-Systemen nur schwer oder mit hohen Kosten für Tiering-Modelle umsetzen. Die Alternative bildet ein "schlankeres" Konzept mit intelligentem Storage-Management.Während auf der Server-Seite die Technik durch die Entwicklung immer neuer CPUs mit den steigenden IT-Anforderungen leicht Schritt halten kann, ist dies auf Storage-Seite nicht so einfach. Das Problem sind veraltete Architekturen fast aller gegenwärtig angebotenen Storage-Systeme. Diese verlassen sich bei der Geschwindigkeit auf die Anzahl der sich darin arbeitenden Festplatten - ein Konzept, das den heutigen Anforderungen kaum noch gerecht wird: Denn die wirklich geschäftskritischen Anwendungen von Unternehmen stellen im weitesten Sinne Datenbanken dar. Diese schreiben und lesen aber nur relativ kleine Datenpakete im Bereich von wenigen KByte auf und von den Festplattensystemen in zufälliger Reihenfolge. Genau dort liegt die eigentliche Herausforderung für Storage-System. Klassische Beschränkungen Um solche kleinen Datenpakete verarbeiten zu können, muss eine Festplatte zunächst den Schreib-/Lesekopf in die richtige Spur bewegen und dann warten, bis der richtige Block durch die Plattenumdrehung unter dem Kopf liegt. Die notwendige Zeit für einen solchen Vorgang liegt im Bereich von drei bis fünf Millisekunden - in der Datenverarbeitung eine Ewigkeit. Selbst schnell drehende Festplatten schaffen nicht mehr als 150 bis 180 dieser Operationen pro Sekunde. Innerhalb der letzten zehn Jahre hat sich die Kapazität der Festplatten zwar verhunderfacht, aber die Geschwindigkeit der einzelnen Festplatten ist kaum angestiegen. Storage-Systeme halten zwar dem Datenwachstum auf diese Weise stand, aber nicht den gestiegenen Geschwind