Doppelt hält besser
Windows zieht in die Rechenzentren ein und erfordert vielfach ein Umdenken in Hochverfügbarkeitsfragen. Die Infrastruktur allein kann nur selten für ausfallsichere Systeme sorgen, zu einem effektiven Gesamtkonzept gehört auch die Software. Ein Replikationsansatz für die Microsoft-Server kann dabei gute Dienste leisten.
"Das Beste aus zwei Welten" war lange Zeit die Leitlinie, nach der viele IT-Abteilungen in den Unternehmen ihre Systemarchitektur geplant und implementiert haben. Unternehmenskritische Anwendungen, die grundlegende Geschäftsprozesse abbilden, liefen in der entsprechend abgesicherten Unix-Welt, während weniger kritische Applikationen bei Microsoft-Lösungen angesiedelt wurden, die eine deutlich geringere TCO versprach. Mittlerweile sind diese beiden Welten miteinander verschmolzen. Auf Windows-Servern laufen Exchange, SQL, Oracle, IIS, Datei- und Druckservices sowie Applikationen wie die Buchhaltungs- oder Logistiksoftware. Die meisten dieser Applikationen sind als kritisch einzustufen und stellen entsprechende Anforderungen hinsichtlich Ausfallsicherheit und Hochverfügbarkeit.
In den vergangenen Jahren haben die Unternehmen viel in die Verfügbarkeit ihrer Systeme investiert - nicht zuletzt auf Grund veränderter rechtlicher Anforderungen wie Kontrag und Sarbanes-Oxley. Auch führt das viel diskutierte Basel II schon vor seiner Verabschiedung dazu, dass die Absicherung der IT-Infrastruktur und der unternehmenskritischen Daten und Anwendungen bei der Kreditvergabe durch die Banken eine wesentliche Rolle spielt und daher zunehmend in den Fokus auch der Geschäftsführung rückt.
Doch trotz der insgesamt wachsenden Investitionen in die Verfügbarkeit werden die Windows-Server oft stiefmütterlich behandelt. Nach wie vor verfügt die Mehrzahl dieser Server über gar keine oder nur gering ausgeprägte Redundanz, und die Spiegelung kompletter Server auf ein Standby-System ist vor allem in mittelständischen Unternehmen ebenso unüblich wie ein redundanter Active-Active-Cluster. Die Verfügbarkeit wird meist nur über ein RAID-System sichergestellt, das diese Aufgabe jedoch nur erfüllen kann, wenn nicht mehr als eine Platte gleichzeitig ausfällt.
Backups erfolgen nach wie vor in definierten Zeitfenstern und nur alle 24 Stunden, und auch die Serviceverträge enthalten oft nur Vereinbarungen über vier bis sechs Stunden Reaktionszeit - so es sie überhaupt gibt.
Es gibt zahlreiche Ansätze, um den Schutz und die Verfügbarkeit von Daten zu verbessern. Von Grund auf redundant ausgelegte Systemarchitekturen wie etwa die von Stratus verringern die Häufigkeit von Hardwareausfällen. Doch auch sie bleiben anfällig gegenüber Ausfällen, die durch Systemüberlastung, Benutzer, Applikationen oder lokale Katastrophen verursacht werden. Und gerade das sind die häufigsten Ausfallursachen.
Auch lokale Cluster erhöhen die Verfügbarkeit, erfordern jedoch relativ hohe Investitionen und benötigen ein gemeinsames Plattensubsystem. Zudem sind auch Cluster-Server nicht für Disaster Recovery geeignet, da sie sich in derselben Niederlassung befinden und so im Katastrophenfall die nötige Datenwiederherstellung nicht leisten können. Die beste Cluster-Technik nützt nichts, wenn die ganze Niederlassung betroffen ist. Zudem stellt das gemeinsam genutzte Plattensubsystem einen Single Point of Failure dar. Selbst wenn die Zuverlässigkeit unzweifelhaft erhöht wird, sind Cluster also kein Allheilmittel.
Ganz oben in der Hierarchie hinsichtlich Kosten und Komplexität stehen spezialisierte Lösungen wie Oracle Parallel Server und Lotus Notes, die ein Unternehmen im Ernstfall handlungsfähig halten können. Allerdings sind solche Lösungen für jede Applikation individuell und lösen nicht das allgemeine Problem der Hochverfügbarkeit im Unternehmen. Dass eine solche Lösung aber unumgänglich ist, zeigt eine Studie des kanadischen Disaster Recovery Institute International. Dieser Studie zufolge müssen 43 Prozent der Unternehmen nach einem Katastrophenfall die Pforten schließen, weil sie nicht in der Lage sind, das Problem zu bewältigen. 29 Prozent derjenigen, die ihre Aktivitäten wieder aufgenommen haben, schließen nach einem Zeitraum von zwei Jahren.
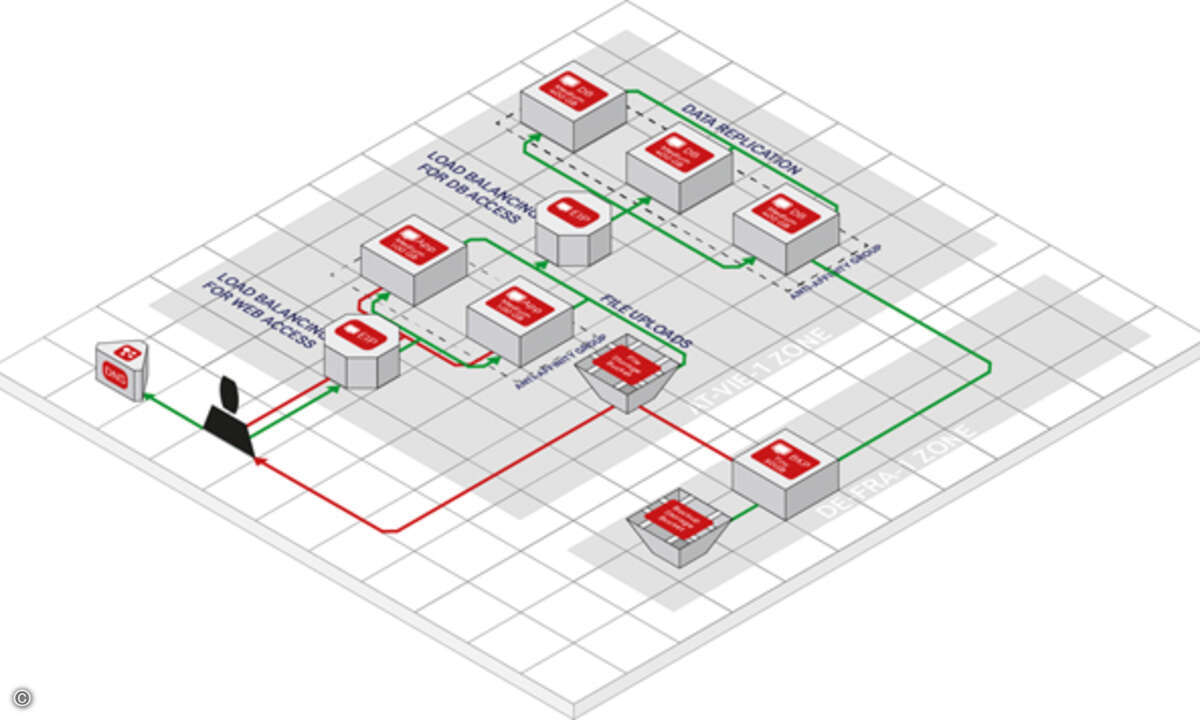
Eine Alternative zu den unzuverlässigen oder teuren Lösungen ist die Replikation von Daten in Echtzeit, wobei abhängig vom Anwendungsfall einer oder mehrere Quellserver auf ebenfalls einen oder mehrere Zielserver repliziert werden. Wird diese Replikation zudem mit einer Failover-Funktionalität kombiniert - übernimmt also der Zielserver bei Ausfall des Quellservers den Namen und die IP-Adresse des Quellservers -, so lässt sich mit relativ geringen Investitionen eine hochverfügbare Umgebung aufbauen.
Die einfachste Art der Replikation von Windows-Servern besteht darin, ganze Dateien zu kopieren - beispielsweise mit Xcopy-Jobs, die über den Scheduler aufgerufen werden. Die Nachteile einer solchen Lösung sind offensichtlich. So werden offene Dateien nicht gesichert, und es gibt keinerlei strukturiertes Reporting oder Management. Einigen dieser Aspekte widmet sich der File Replication Service (RFS), doch auch damit bleibt die Replikation auf Dateiebene ein bandbreitenintensives Unterfangen. Zum einen werden grundsätzlich komplette Dateien übertragen, auch wenn es nur geringfügige Änderungen gegeben hat, und zum anderen muss die gesamte Datei auch in einem Zuge kopiert werden, was die verfügbare Bandbreite unter Umständen komplett auslastet. Diese Art der Replikation eignet sich daher nur für Umgebungen mit relativ kleinen Dateien, die zudem nicht gemeinsam genutzt werden sollten, um keine Konflikte zu erzeugen.
Replikation auf Anwendungsebene
Bei der Replikation auf Anwendungsebene macht man sich spezielles Wissen um die inneren
Mechanismen einer Applikation zunutze. Dabei sendet eine Instanz der Applikation Teile ihrer Daten
an eine weitere Instanz, wie es beispielsweise der Microsoft SQL Server mit seinen
Transaktions-Logs machen kann. Dieses Vorgehen ist naturgemäß sehr anwendungsspezifisch, und die
Möglichkeiten hängen sehr stark von der Architektur der jeweiligen Anwendung ab. Applikationen, die
keine Replikationsmechanismen zur Verfügung stellen, sind nach wie vor auf andere Weise zu sichern.
Sollen Windows-Server unabhängig von der jeweiligen Applikation repliziert werden, benötigt man ein
generisches Software-Tool, wie es etwa "Doubletake" von Sunbelt Software darstellt. Diese
Replikationssoftware installiert Treiber, die I/O-Requests des Betriebssystems abfangen und
filtern, bevor diese an die Hardware weitergereicht werden. Auf diese Weise können Transaktionen
transparent an den Zielserver übertragen werden, auf dem natürlich die gleichen Anwendungen laufen
müssen. Insofern ähnelt das Verfahren sehr stark demjenigen, das bei (teuren) Hardwarelösungen
verwendet wird.
Dieses Verfahren ist nicht nur applikationsunabhängig, sondern ermöglicht auch die nachträgliche
Implementierung der Replikation auf vorhandenen Servern. Da lediglich I/O-Requests auf Byteebene
repliziert werden, ist das Verfahren für die Applikation völlig transparent – der Administrator
muss sie weder neu installieren noch modifizieren. Zudem sinken die Anforderungen an die Bandbreite
sehr deutlich, da etwa die Änderung von 12 Bytes auf dem Quellserver lediglich die Einstellung eben
dieser 12 Bytes in die Replikations-Queue zur Folge hat anstelle des 64-KByte-Blocks oder gar der
gesamten Datei.
Zudem sind auf diese Weise Dateien und Folder geschützt und nicht ganze Volumes, sodass die
Größe des Ziel-Volumes nur der tatsächlich zu sichernden Datenmenge auf dem Quell-Volume
entsprechen muss. Ferner führt die geringe zu übertragende Datenmenge dazu, dass auch langsame
WAN-Verbindungen für die Replikation genutzt werden können. Eine einfache TCP/IP-Verbindung
bewältigt normalerweise die blockweise asynchrone Replikation ohne Probleme, vor allem wenn die
Replikationsparameter entsprechend individuell konfigurierbar sind. In einer solchen Anordnung mit
räumlich getrennten Quell- und Zielservern ist dann auch die schnelle Wiederaufnahme des Betriebs
nach einer lokalen Katastrophe möglich.
Eine solche Replikationslösung ist sowohl in One-to-Many- als auch in Many-to-One-Szenarien
einsetzbar. Da alle Daten einschließlich offener Dateien in Echtzeit auf die Zielsysteme übertragen
werden, kann dieses durch Übernahme des Namens und der IP-Adresse wirkungsvoll an die Stelle des
ausgefallenen Servers treten. Die Replikation offener Dateien ist eine Grundvoraussetzung, wenn es
um eine Hochverfügbarkeitslösung für SQL-Datenbanken oder Exchange Server geht. Bei
Failover-Konfigurationen muss natürlich sichergestellt sein, dass das übernehmende Zielsystem
überhaupt Client-Anfragen unter der vom Quellserver übernommenen IP-Adresse entgegennehmen kann.
Subnetze und Namensauflösung müssen daher entsprechend konfiguriert sein. Gegebenenfalls sind
skriptgesteuerte Änderungen am Active Directory oder am WINS/DNS erforderlich.