Hadoop verspricht hohe Skalierbarkeit und Flexibiltät bei niedrigen Kosten
- Hadoop wird zur Basis für Big-Data-Lösungen
- Hadoop verspricht hohe Skalierbarkeit und Flexibiltät bei niedrigen Kosten
- Datenhaltung neuer Art erforderlich
- Business Intelligence für Big Data
- Startups auch bei der Auswertung von Hadoop-Daten aktiv
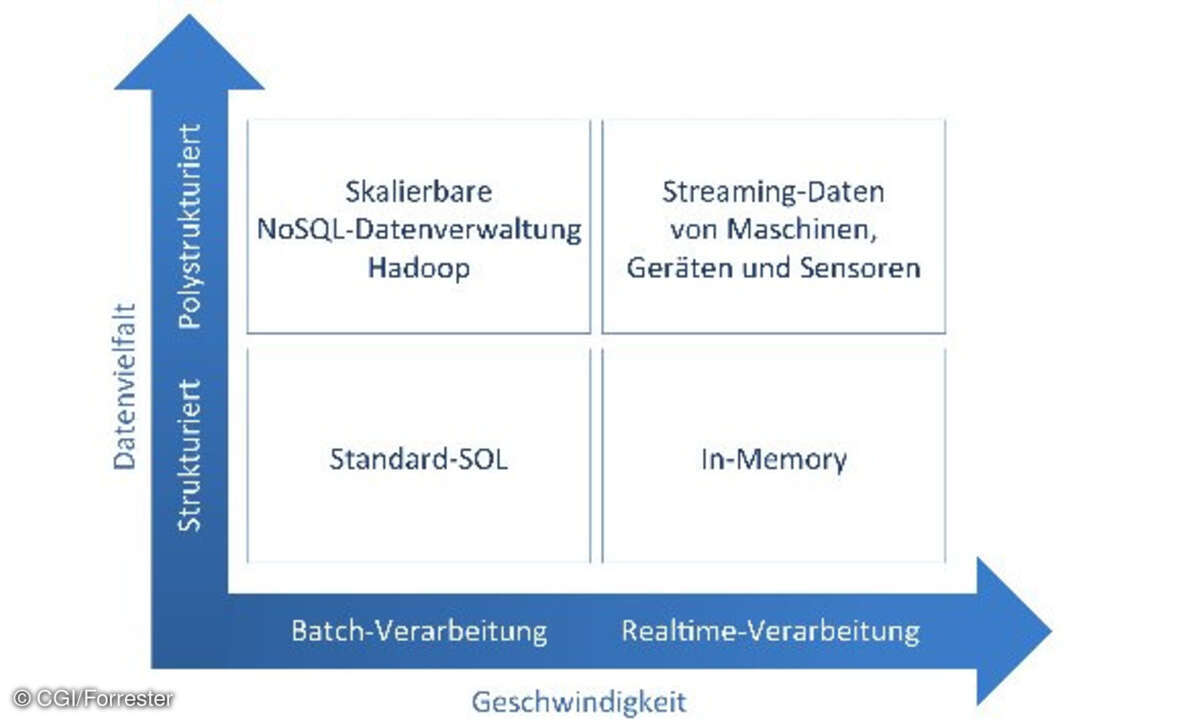
Als Basistechnologie setzt sich derzeit die quelloffene Software Hadoop durch. Es handelt sich dabei um ein in der Programmiersprache Java erstelltes Framework für zuverlässige datenintensive verteilte Anwendungen mit x86-basierten Systemen. Unterstützt werden Tausende von Rechnerknoten und Petabytes an Daten. Den Ausgangspunkt bildeten Papiere des Suchmaschinenriesen Google aus dem Jahr 2004 zu einem Verfahren namens MapReduce sowie zum Dateisystem. Seit 2008 ist die Technologie unter den Fittichen der Apache Software Foundation und wird dort in mehreren Teilprojekten weiterentwickelt.
Das Hadoop Distributed File System (HDFS) ist ein hochverfügbares Dateisystem, in dem sehr große Datenmengen abgelegt werden können. HBase stellt eine skalierbare Datenbank zur Verwaltung sehr großer Datenmengen in einem Hadoop-Cluster zur Verfügung. MapReduce implementiert ein Verfahren zur parallelen Verarbeitung sehr großer Datenmengen in Clustern. Bei Hive geht es um eine Data-Warehouse-Schicht, die auf Hadoop-Datenhaltungssystemen aufsetzt, um beispielsweise Zusammenfassungen und Ad-hoc-Abfragen zu erleichtern. Weitere Projekte sind die Sprache Pig zur Programmierung, Zookeeper zur Konfiguration sowie Chukwa zur Überwachung von Hadoop-Systemen.
Hadoop verspricht niedrige Kosten, hohe Skalierbarkeit im Hinblick auf die Menge und Flexibilität hinsichtlich der Struktur der Daten. Im Einsatz ist die Software bereits beispielsweise bei den Online-Riesen AOL und Amazon, engagiert ist auch der Suchmaschinenanbieter Yahoo. Ausgereift und für den robusten Einsatz in der Wirtschaft ohne Einschränkungen geeignet ist die Hadoop-Software noch nicht, so wie auch die Handhabung und Nutzung der Big Data generell noch in den Kinderschuhen steckt.